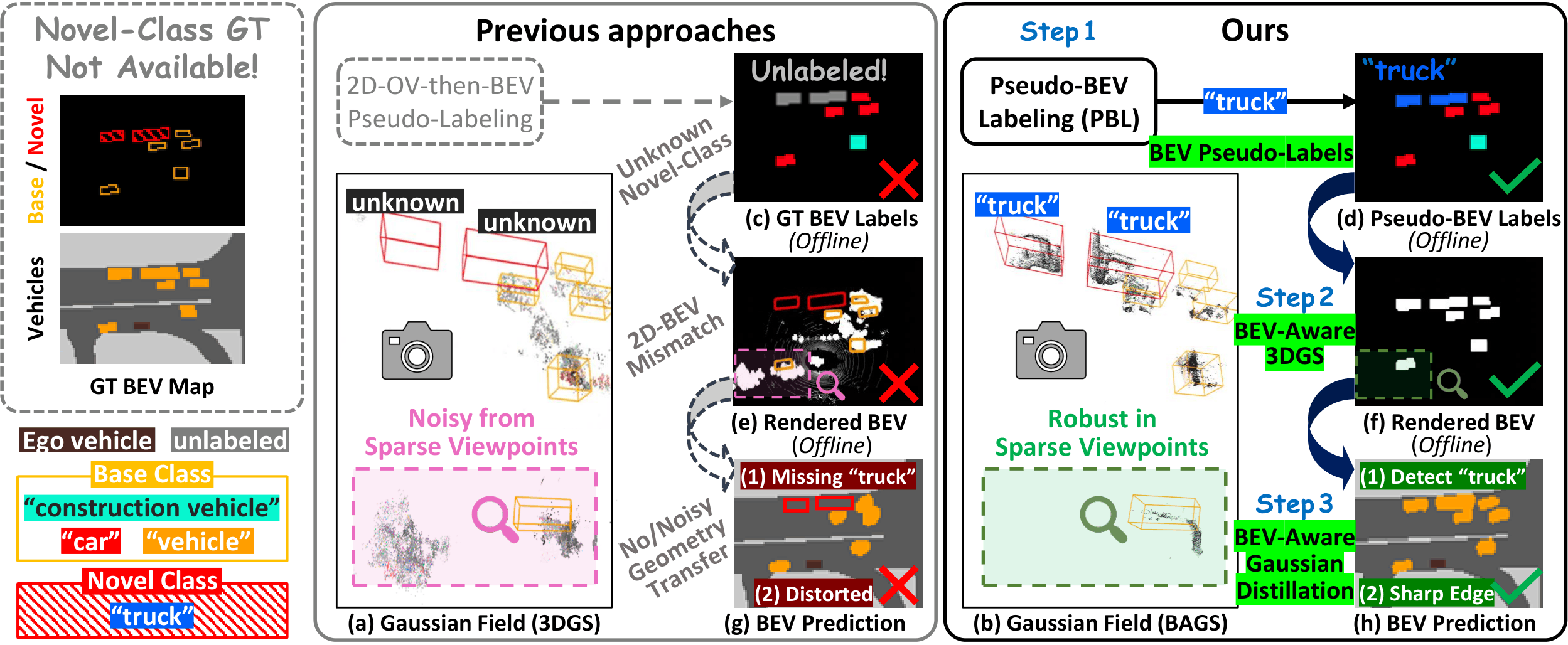
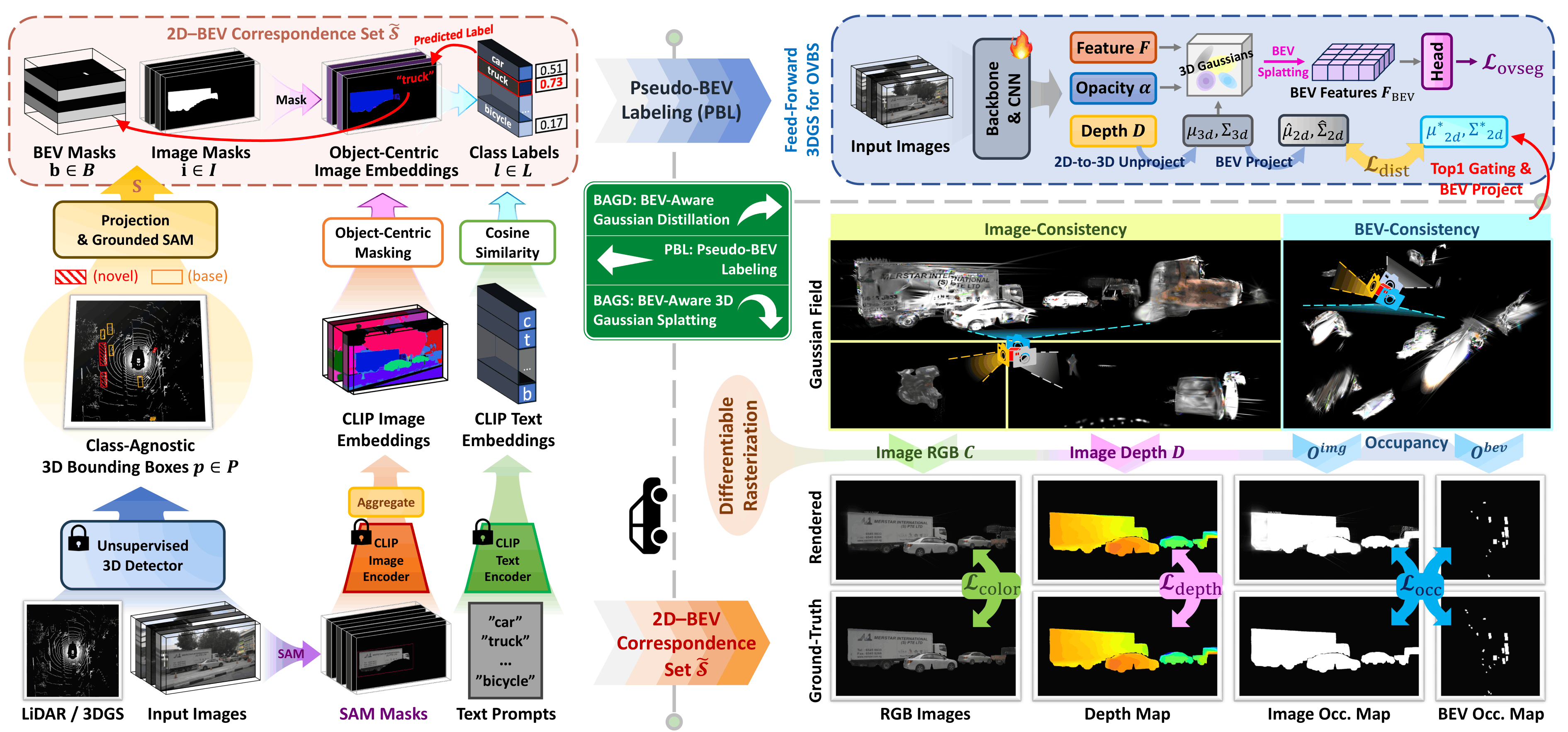
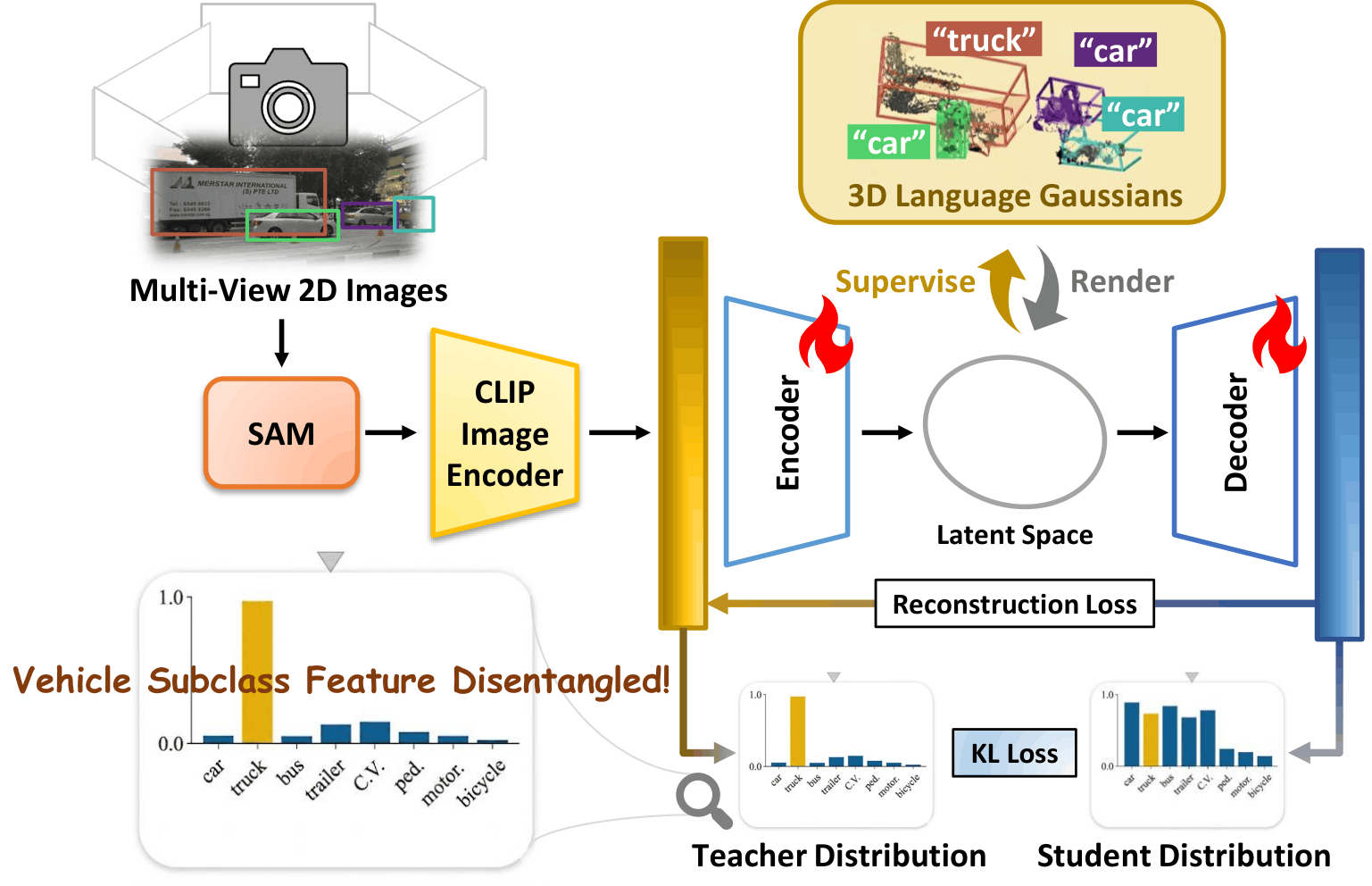
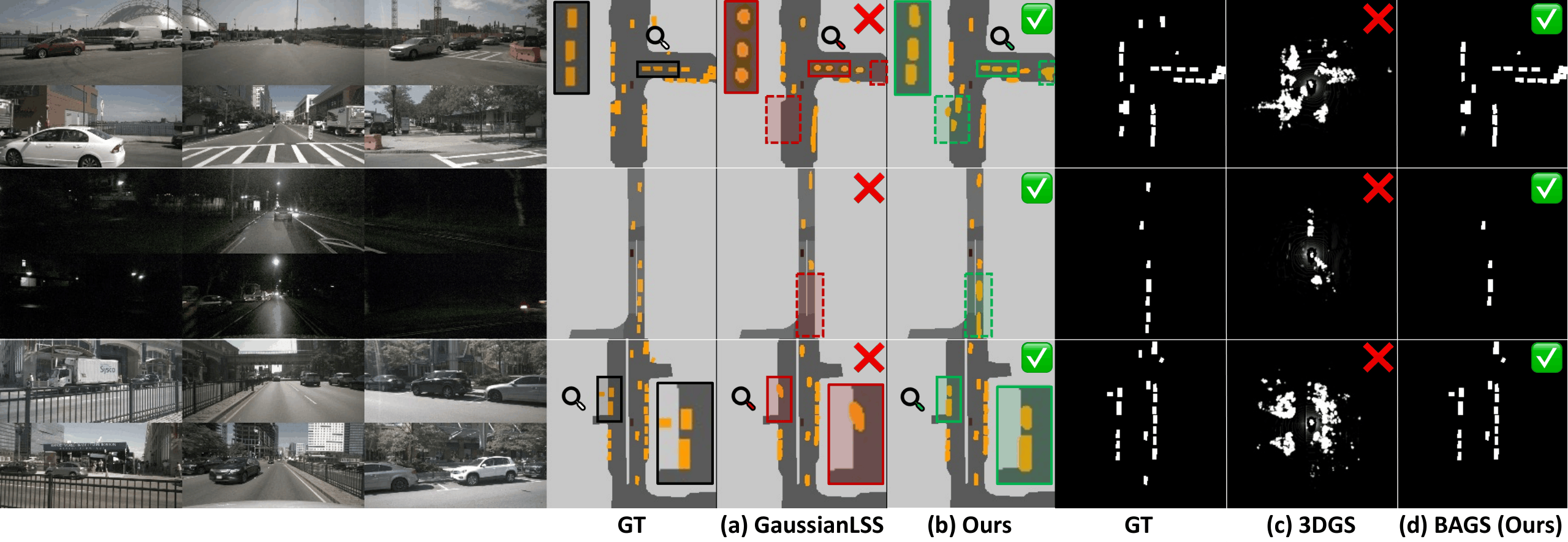
Bird's-eye view (BEV) perception fuses multi-camera images into a unified top-down representation for autonomous driving. Despite recent progress, state-of-the-art methods remain confined to closed-set scenarios, making them vulnerable to unpredictable real-world environments. In this work, we introduce open-vocabulary BEV segmentation (OVBS), which leverages vision-language models (VLMs) to recognize categories beyond the training set while maintaining precise BEV perception and real-time efficiency. A key challenge in OVBS lies in the 3D geometric inconsistency inherent in the ill-posed lifting of 2D VLM semantics into BEV. To address this, we propose OVBEVSeg, a geometry-aware OVBS framework that enhances efficient Gaussian splatting (GS)-based unprojection by leveraging robust 3D geometric constraints across three progressive stages: (1) 2D-to-BEV pseudo-labeling via reliable 3D projection for OV generalization; (2) joint 2D–BEV per-scene optimization with BEV structural constraints for 3D geometric consistency; and (3) 3D geometric distillation for efficiency. On the nuScenes dataset, OVBEVSeg achieves state-of-the-art performance, outperforming closed-set methods by 15.3 mIoU on unseen categories. Remarkably, despite being entirely label-free, it remains competitive with self- and semi-supervised baselines trained with up to 40% of ground-truth annotations. Furthermore, it achieves 2.5× faster inference with only 0.22× the memory consumption of projection-based methods.