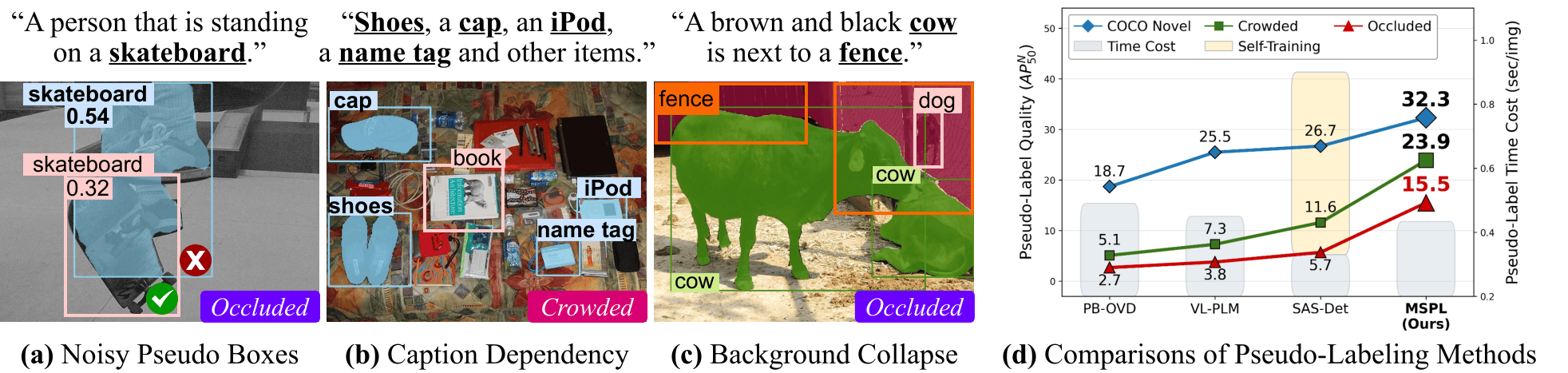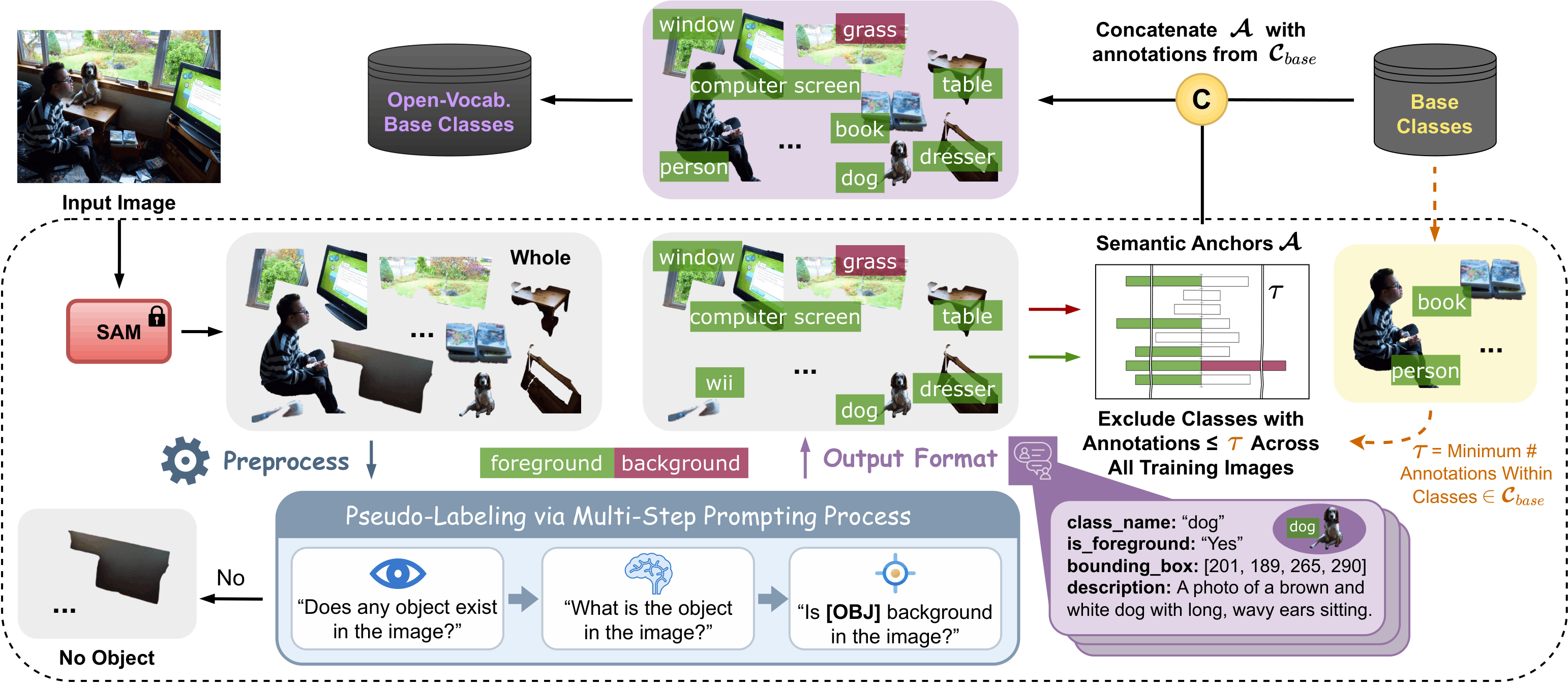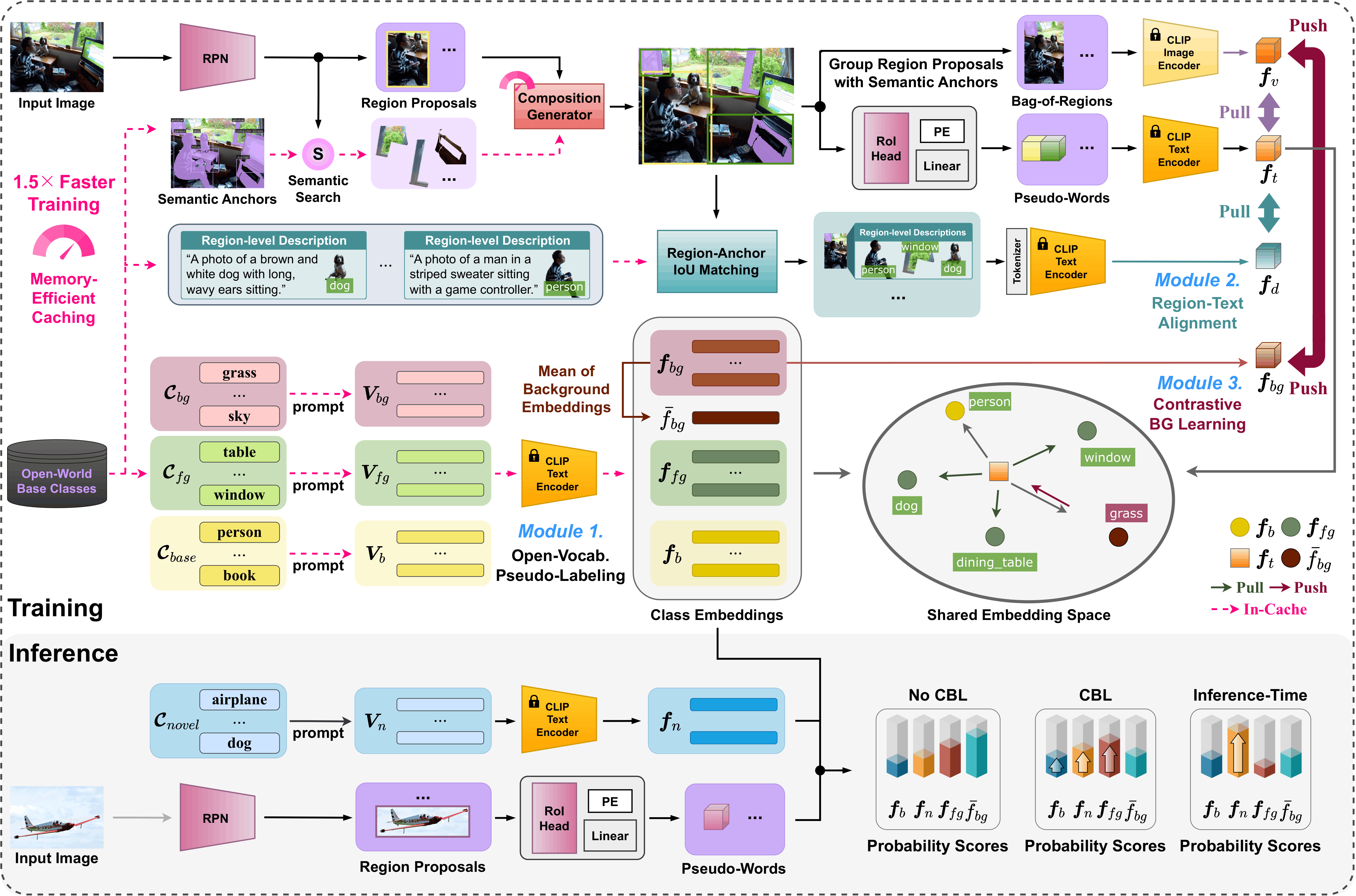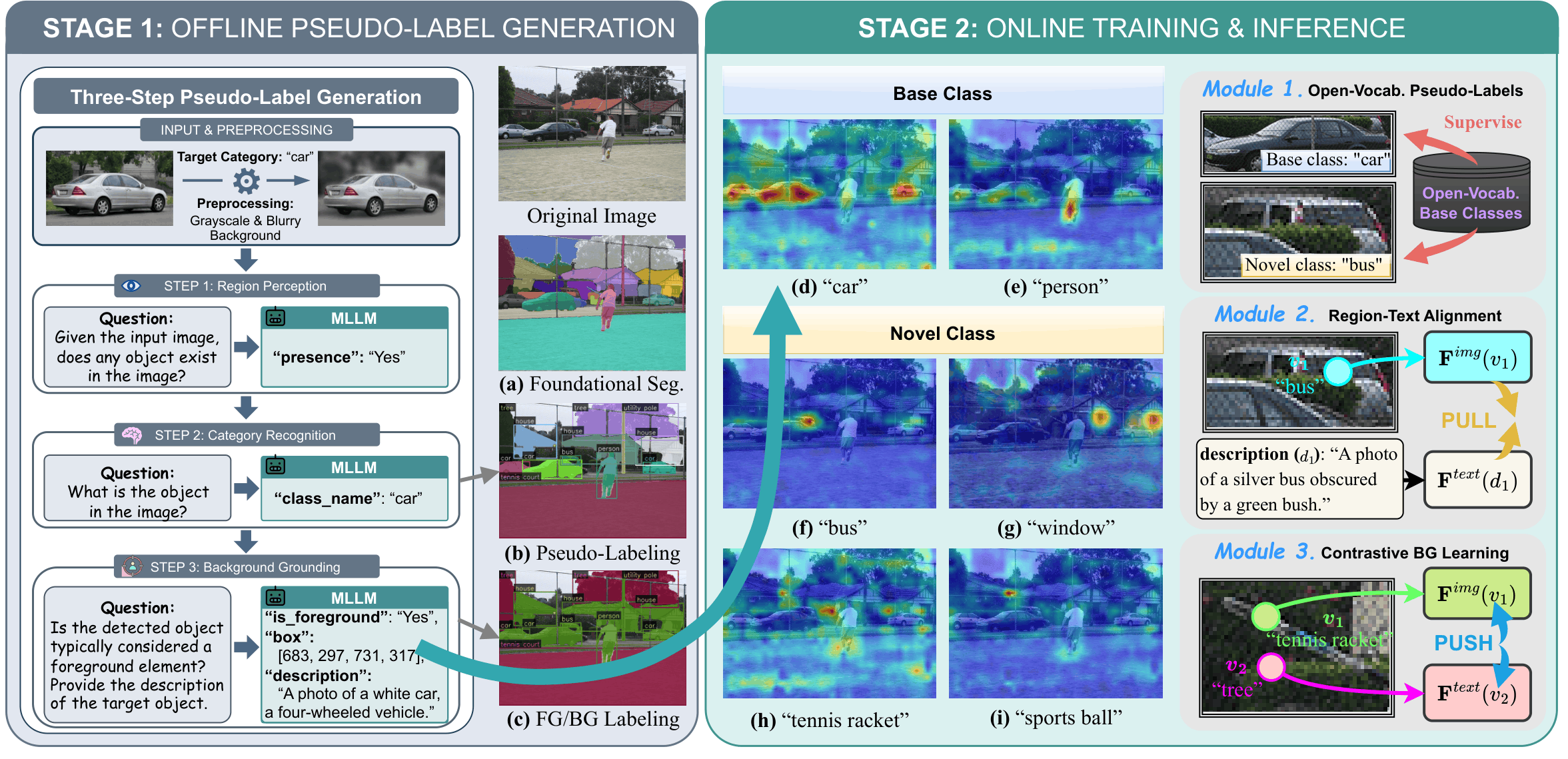
Open-vocabulary object detection (OVD) aims to recognize and localize object categories beyond the training set. Recent approaches leverage vision-language models to generate pseudo-labels using image-text alignment, allowing detectors to generalize to unseen classes without explicit supervision. However, these methods depend heavily on single-step image-text matching, neglecting the intermediate reasoning steps crucial for interpreting semantically complex visual contexts, such as crowding or occlusion. In this paper, we introduce MSPL, a framework that incorporates multi-step visual reasoning into the pseudo-labeling process for OVD. It decomposes complex scene understanding into three interpretable steps—object localization, category recognition, and background grounding—where these intermediate reasoning states serve as rich supervision sources. Extensive experiments on standard OVD evaluation protocols demonstrate that MSPL achieves state-of-the-art performance with superior pseudo-labeling efficiency, outperforming the strong baseline by 9.4 AP50 for novel classes on OV-COCO and improving box and mask APr by 3.2 and 2.2, respectively, on OV-LVIS.